


bing An alert is coming in, but unfortunately your network is unreachable. What now? How would you fix this problem when you can't access your network? You don't want to go to the datacenter, because you're a RelaxOps (tm)! Good that you are prepared and have an out-of-band management network which lets you access all your network gear and probably fix the issue in no time. Some hints, tipps, tricks and lessons learned.
Typical failures
Way too many things can go wrong in your network so that you can no longer access services using your production network, I'm sure everyone is aware of that.
Here are some possible root causes:
- (D)DoS attack
Some bad guys fill up your links with unneccessary traffic and eat up
all resources, also the ones needed to counter the attack. - Misconfiguration
We are all human beings configuring our systems and we are not fool-proof. - Software bugs
Also software engineers make mistakes. Crashing or missbehaving daemons
can kill a whole network. - Filled up, saturated links
Network links (f.e. switch uplinks) are always overbooked and if they fill up, your devices are not reachable anymore. - 3rd party fails
You are most likely dependent of some third party services like transit,
peering, ... and if they mess up, you will be affected for sure. - Your own story goes here
...
You are prepared, aren't you? A prepared admin can relax and concentrate
on fixing the real problem, not on how to access the systems. Be a RelaxOps.

Scenarios
The mentioned things which can go wrong can affect a single server, a whole rack, many racks, or an entire datacenter, depending on your environment. We start with a single server and then go up until we reach a multi-datacenter environment.
[A] One server
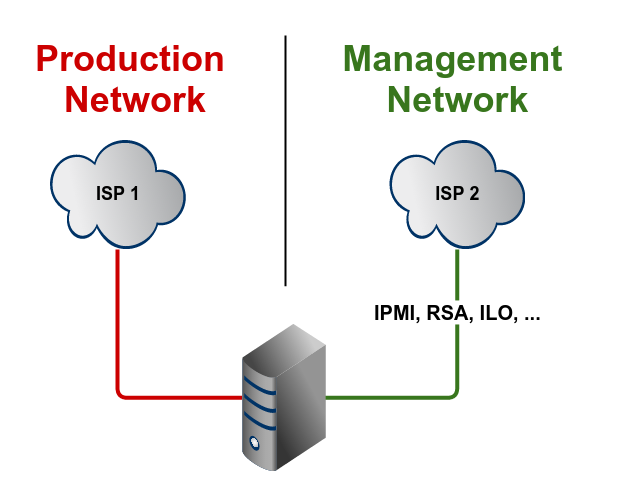
A single server should never have only one network connection, because this one will fail, sooner or later. All the mentioned failures can/will happen to this one and only network connection.
Best practice would be to have at least two connections: One for the production traffic and one for the onboard IPMI (RMM, RSA, IMM, and so on) controller. If something goes wrong with the main connection, you'll still be able to access your server on a different path. These two connections should of course not be connected to the same switch in the same network (facepalm alert).
If your server does not have an IPMI controller, there are other ways to have some sort of real out-of-band connection, f.e. on linux you can use
network namespaces to create an isolated management environment.
A nice to have addition would be to have a separate network for "meta" traffic like backup, to minimize the possibility to saturate the production traffic link.
[B] A rack
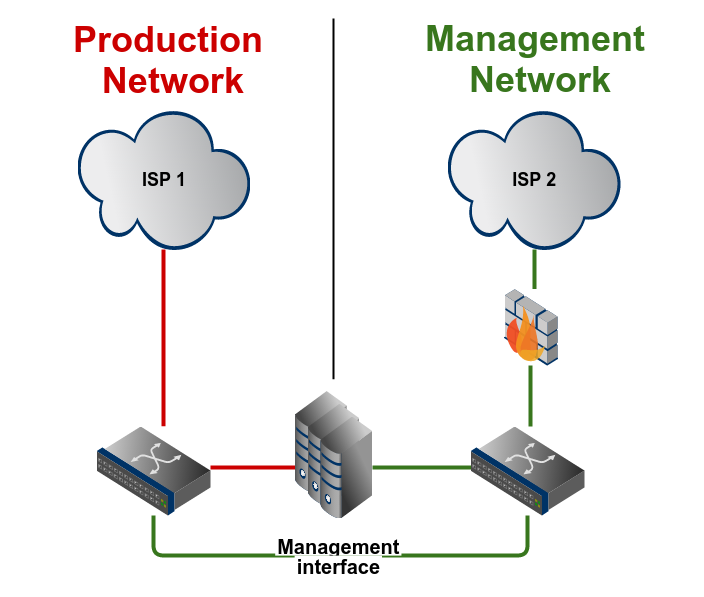
Having a rack full of own equipment, it's now not enough to just think about one server, but about all the devices in the management domain.
It makes sense to build a management network completely separated from the production traffic network. This means: Use dedicated equipment, because re-using the production network using f.e. VLANs does not make sense. If your production network fails, most likely other VLANs could also be affected (f.e. a saturated uplink to an access switch also affects all other traffic on this physical interface).
You want to connect all management interfaces from your devices to this management network: management ports of switches and routers, IPMI, APC PDU, and so on. Using a firewall and accessing them via a VPN gateway (f.e. OpenVPN) also protects these devices from bad guys.
Accessing this management network from the outside of the rack (mainly the Internet) should neither be done using the main network. A dedicated out-of-band uplink ensures that in case of a link failure of the main connection you are still able to access your network gear.
Many professional ISPs have an out-of-band connection to offer. The best case would be to have this connection from a different ISP than the main connection. Another possibility would be to use a mobile network modem, so that you are completely independent of the datacenter connections.
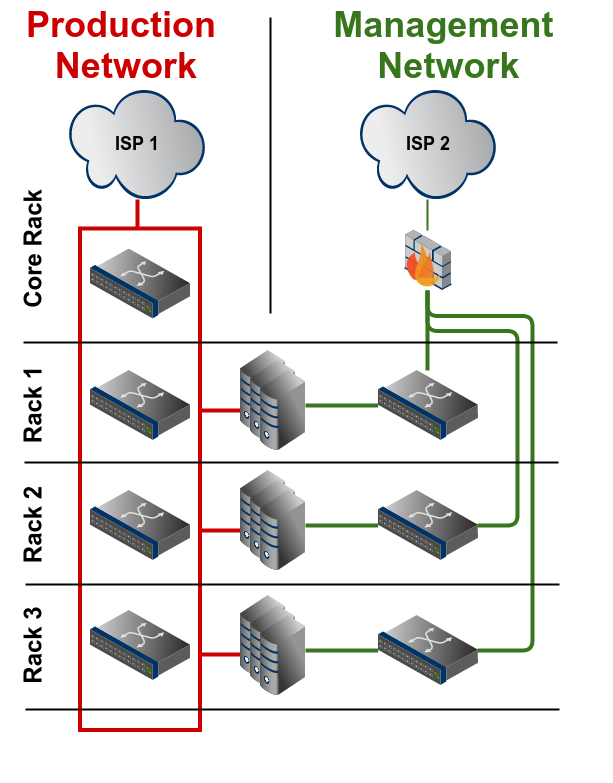
[C] More than one rack in one datacenter
This extends the scenario B. Every rack should have a dedicated switch for the management network. These switches can then be connected to a main rack which holds the other components of the management network, like
the Internet uplink and a VPN gateway. These connections should be done using separate patchings, don't reuse existing connections between these racks.
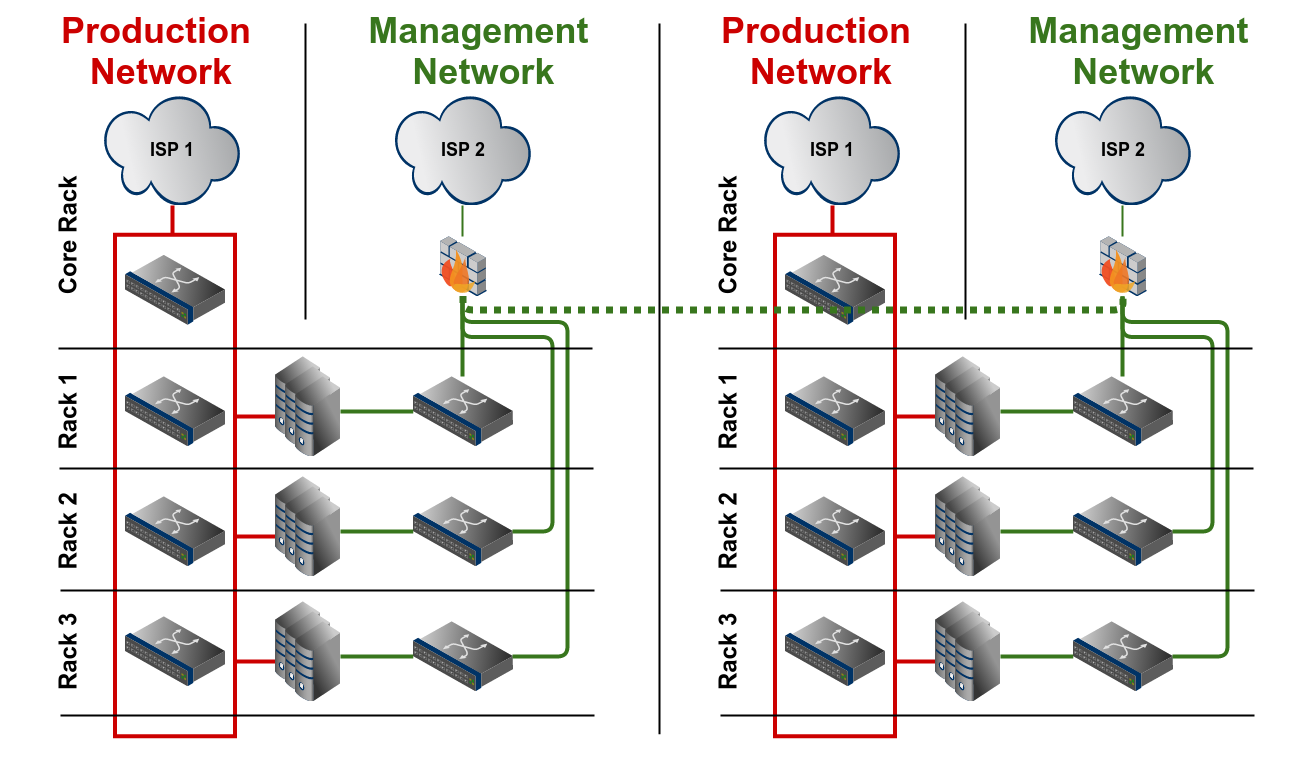
[D] Racks spread in different datacenters
A separate management network in each datacenter ensures independency between the different management domains. If really needed, an interconnection could be made to access the management network in the other datacenter if the access components (Internet uplink, VPN) fail, but the connection should not be necessary for the functionality of the management network.
Security and availability
Security
The management network holds the essential parts of the whole network and
can be an interesting attack vector, so this network must be well protected and also well maintained with security patches.
Consider having an SSH jumphost to access all management network devices. If someone needs to connect to this network segment, the only way is to log-in to the jumphost and from there to the devices. The SSH jumphost could also hold a passphrase protected SSH key which can be used to access these devices. It would also be an option to tie this SSH key to the IP of the jumphost so that it cannot be used from another source IP address.
This SSH jumphost needs special security precaution:
- No other services than an SSH service running on this server
- Fail2ban or a similar tool to lock out attackers if they try to bruteforce the jumphost
- IPtables to implement firewall rules in case of attacks (f.e. enable
a country block which only allows IPs from Switzerland)
Another way to access the management network could be over an OpenVPN tunnel. If some monitoring services or other tools need access to the management network, a static OpenVPN tunnel from the server to the management network could be a nice and easy solution.
While planning the security aspects of the management network, the usage of the "Onionskin Security Principle" helps to understand which devices should have access to which segment:
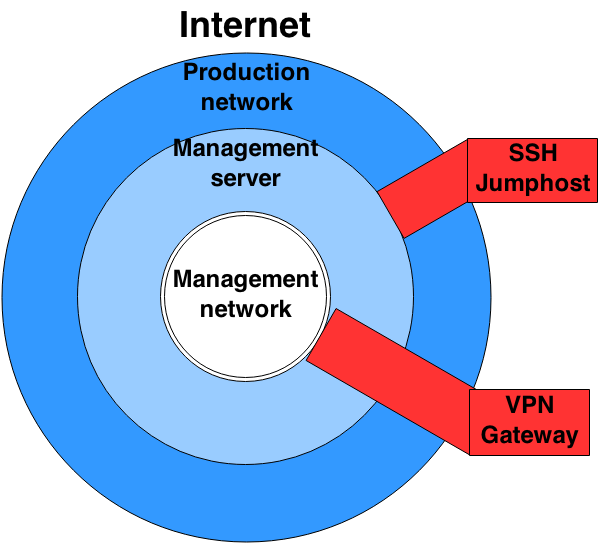
Availability
You want to make sure that the management network is always available, mainly in case of emergencies you want to be sure that this very important network and its supporting services (firewall, VPN) are available. There are many nice open source projects and technologies out there to make this possible: pfSense with CARP, Keepalived, Pacemaker and many more.
And don't buy the cheapest hardware. F.e. it should have redundant power supplies.
General
Some other things to take into consideration:
Serial terminal server
Management interfaces of network devices can also fail, therefore a serial
terminal server which connects the serial management interface to the network can be a last resort. Also if a network device needs to be factory-reset and configured from the ground up the serial terminal server is your best friend doing this. And last but not least you can see the boot process and maybe start memory tests, boot from a secondary partition, and so on.
Remote power management
Sometimes a hard-reset is the only way to fix a problem, a remote manageable power bar combined with a serial server can help fixing such really nasty situations.
IP addressing
The management network does not necessarily need public IP addresses. I
recommend using IP addresses from the private IP space (RFC 1918) and the usage of a VPN tunnel to reach these hosts. If your equipment supports IPv6, go for it! But most likely, the IPv6 support on many special devices (like IPMI adapters) is poor to non existent, so maybe IPv4 will be a safer option for the moment.
Planning the IP addressing scheme also makes sense. If you're able to determine the management IP address from the device type and/or location, you're a bit more prepared and relaxed if you don't have the list available in the very special moment of an incident (maybe dns is also not working, your /etc/hosts is not available or your .ssh/config is broken too).
KISS
Keep it simple, stupid.: You want to be sure that your management network is as simple as possible, it doesn't need any routing protocols nor spanning-tree or other protocols which can fail or are susceptible for misconfigurations. It's much better that you really know what's going on and don't rely on "magic". If you know your failure domain (f.e. making a loop which is not prevented due to spanning-tree disabling), you can react much better.
Vendor diversity
Having equipment from different vendors in your management and production
network helps to prevent the possibility of having the same software bug in both network segments. If this is not possible, consider running different firmware releases in each of these segments. The management network normally doesn't need the latest feature releases (see KISS).
Be prepared
A well prepared administrator (also called RelaxOps) is the best that can happen in case of an emergency. This means:
- All documentation is up to date, well known where to access and accessible even in the case of a network failure (a local copy or a copy hosted externally)
- Administrators are trained and know how to use the management network
- SSH connections are prepared (
.ssh/config) and keys deployed - The management network is regulary tested for its functionality
(Why not use it daily?)
Full example
An full example of a management network
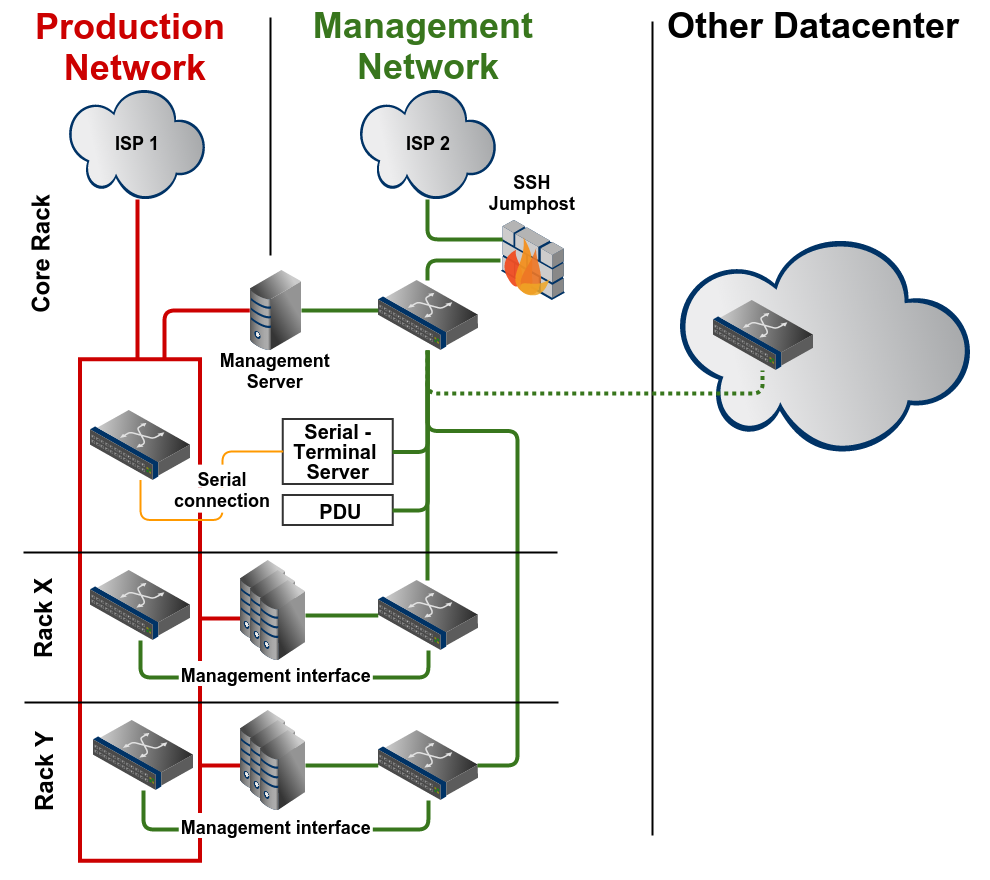
Link to slides
You can download the slides here: HTML version / PDF version



