


This article has originally been written for SysAdvent 2015
Over the last year there has been a lot of buzz around open-source Platform-as-a-Service (PaaS) tools. This blog will give you an overview of this topic and some deeper insight into Red Hat OpenShift 3. It will talk about the kind of PaaS tools you install on your own infrastructure - be it physical, virtual or anywhere in the cloud. It does not cover installation atop Heroku or similar services, which are hosted PaaS solutions.
But what exactly is meant by PaaS?
When we talk about PaaS, we mean a collection of services and functions which serve to orchestrate the processes involved with building software up to running it in production. All software tasks are completely automated: building, testing, deploying, running, monitoring, and more. Software will be deployed by a mechanism similar to "git push" to a remote source code repository which triggers all the automatic processes around it. While every PaaS platform behaves a bit differently, in the end they all do the same function of running applications.
Regarding running an application within a PaaS, the application should optimally be designed with some best practices in mind. A good guideline which incorporates these practices is commonly known as the The Twelve-Factor App.
Short overview of Open Source PaaS platforms
There are a lot of Open Source PaaS tools in this space as of late
- Dokku: http://progrium.viewdocs.io/dokku/
A simple, small PaaS running on one host. Uses Docker and Nginx as the most important building blocks. It is written in Bash and uses Buildpacks to build an application specific Docker container. - Deis: http://deis.io/
The big sister of Dokku. Building blocks used in Deis include CoreOS, Ceph, Docker, and a pluggable scheduler (Fleet by default, however Kubernetes will be available in the future). Buildpacks are used for creating the runtime containers. At least three servers are needed to effectively run Deis. - Tsuru: https://tsuru.io/
Similar to Deis, but says it also supports non-12-Factor apps. There is even a possibility to manage VMs, not only containers. This, too, uses Docker as building block. Other components like scheduler are coming from the Tsuru project. - Flynn: https://flynn.io/
Also similar to the two tools above. It also uses Docker as backend, but uses many project specific helper services. At the moment, only PostgreSQL is supported as a datastore for applications. - Apache Stratos: http://stratos.apache.org/
This is more of a framework than just a "simple" platform. It is highly multi-tenant enabled and provides a lot of customization features. The architecture is very complex and has a lot of moving parts. Supports Docker and Kubernetes. - Cloud Foundry: https://www.cloudfoundry.org/
One of the biggest player besides OpenShift in this market. It provides a platform for running applications and is used widely in the industry. Has a steep learning curve and is not easily installed,configured, or operated - OpenShift: http://www.openshift.org/
Started in 2011 as a new PaaS platform using it's own project specific technologies, has been completely rewritten in v3 using Docker and Kubernetes as the underlying building blocks.
OpenShift
There are some compelling reasons to look at OpenShift:
- Usage of existing technology
Kubernetes and Docker are supported by big communities and are good selections to serve as central components upon which OpenShift is built. OpenShift "just" adds the functionality to make the whole platform production-ready. I also like the approach of Red Hat to completely refactor OpenShift V2 to V3, taking into account what they have learned from older versions and not just simply trying to improve the old code base on top of Kubernetes and Docker. - Open development
Development happens publically on GitHub: https://github.com/openshift/origin. OpenShift Origin is"the upstream open source version of Red Hat's distributed application system, OpenShift" per Red Hat. - Enterprise support available
Many enterprises want to or need to have support contracts available for the software which they run their business upon. This is completely possible using the OpenShift Enterprise subscription which gets you commercial support from Red Hat. - Excellent documentation
The documentation at https://docs.openshift.org/latest/welcome/index.html is very well structured, allowing for rapid identification of a topic youre seeking. - My favorite functions
There are some functions which I like the most on OpenShift:- Application templates: Define all components and variables to run your application and then instantiate it very quickly multiple times with different parameters.
- CLI: The CLI tool "oc" is very well structured and you get it very quickly how to work with it. It also has very good help instructions integrated, including some good examples.
- Scaling: Scaling an application just takes one command to start new instances and automatically add them to the load balancer.
So why not chose Cloud Foundry? At the end of the day, everyone has their favourite tool for their own reasons. I personally found the learning curve for Cloud Foundry to be too steep. I didn't manage to get an installation up and running with success. Also I had lots of trouble to understand the things around BOSH, a Cloud Foundry-specific configuration management implementation.
Quick Insight into OpenShift 3 - What does it look like?
OpenShift consists of these main components:
- Master
The API and Kubernetes Master / Scheduler - Nodes
Runs pods, including the workload - Registry
Hosts docker images - Services / Router
Takes client requests and routes them to backend application containers. In a default configuration it's a HAProxy load balancer, automatically managed by OpenShift.
For a deeper insight, consult the OpenShift Architecture
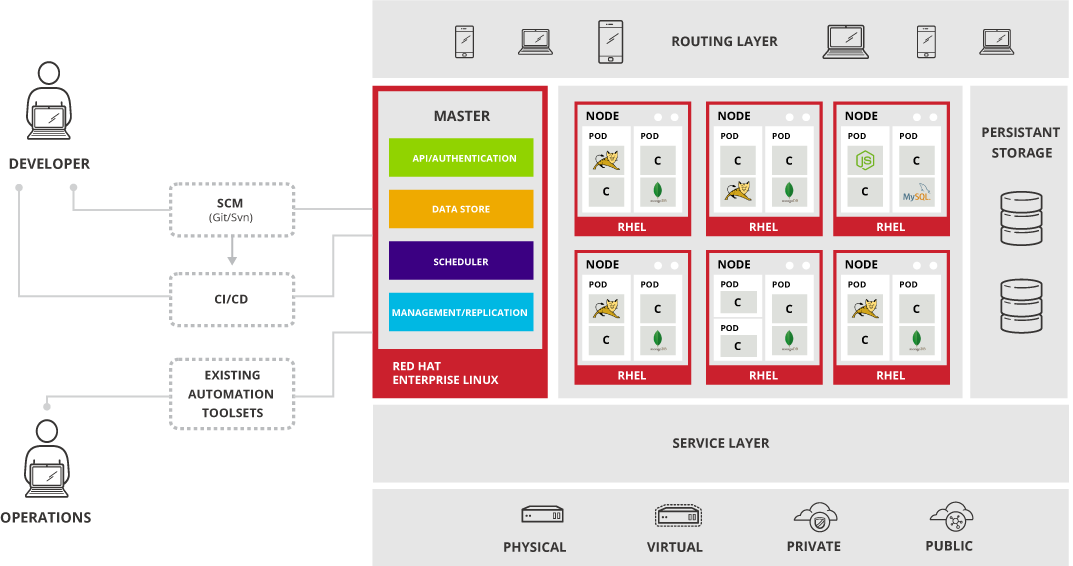
OpenShifts core is Kubernetes with additional functionality for application building and deployment made available to users and operators. So it's very important to understand the concepts and the architecture of Kubernetes. Consult the official Kubernetes documentation to learn more: http://kubernetes.io/v1.1/
Communication between clients and the OpenShift control plane happens over REST APIs. The oc application, available via the OpenShift command-line client, gives access to all the frequently-used actions like deploying applications, creating projects, viewing statuses, etc.
Every API call must be authenticated. This authentication is also used to check if you're authorized to execute the action. This authentication component allows for OpenShift to support multi-tenancy. Every OpenShift project has it's own access rules. Projects are separate from each other. On the network side, they can be strictly isolated from each other via the ovs-multitenant network plugin. This means many users can share a single OpenShift platform without interfering each other.
Administrative tasks are done using oadm within the OpenShift command-line client. Example tasks involve operations such as deploying a router or a registry.
There is a helpful web interface which communicates to the master via the API and provides a graphical visualization of the cluster's state.
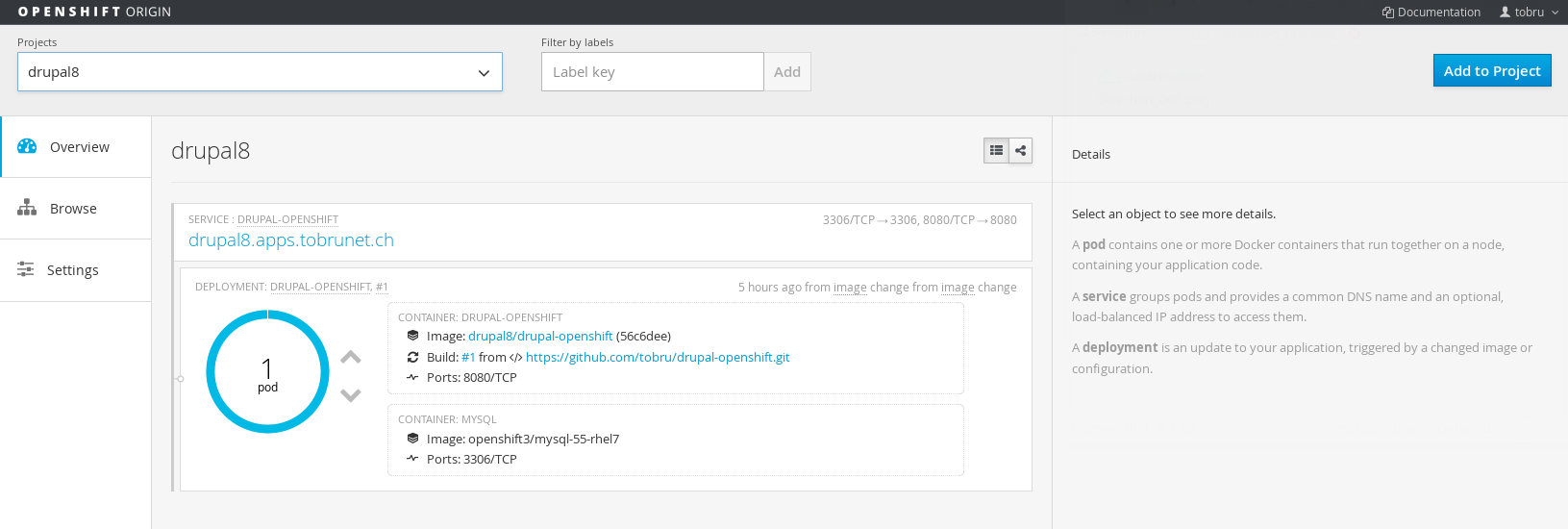
Most of the tasks from the CLI can also be accomplished via the GUI.
To better understand OpenShift and its core-component Kubernetes, it's important to understand some key terms:
- Pod
In Kubernetes, all containers run inside pods. A pod can host a single container, or multiple cooperating containers*". Roughly translated, this means that containers share the same IP address, the same Docker volumes and will run always on the same host. - Service
A pod can offer services which can be consumed by other pods. Services are addressed by their name. This means for example a pod provides a HTTP service on the name "backend" on port 80. Another pod can now access this HTTP service by just addressing the namespace of “backend”. Services can be exposed externally from OpenShift using an OpenShift router. - Replication Controller
A replication controller takes care of starting up a pod and keeping it running in the event of a node failure or any other disruptive event which could take a pod down. It is also responsible for creating replication pods in an effort to horizontally scale the lone pod.
Quickstart 3-node Origin Cluster on CentOS
There are a number of good instructions how to install OpenShift. This section will just give a very quick introduction to installing a 3-node (1 master, 2 nodes) OpenShift Origin cluster on CentOS 7.
If you want to know more details the OpenShift documentation at Installation and Configuration is quite helpful. The whole installation process is automated using Ansible, all playbooks are provided by the OpenShift project on Github. You also have the option to run an OpenShift master inside a Docker container, as a single binary or installing it from source. However the Ansible playbook is quite helpful for getting started.
Pre-requisites for this setup
- Three CentOS 7 64-Bit VMs prepared, each having 4+GB RAM, 2 vCPUs, 2 Disks attached (one for the OS, one for Docker storage). The master VM should have a third disk attached for the shared storage (exported by NFS in this example), mounted under
srv/data. - Make sure you can access all the nodes from the master using SSH without a password. This is typically accomplished using ssh keys. The above user also needs sudo rights, typically via the
NOPASSWDoption in typical Ansible fashion. - A wildcard DNS entry pointing to the IP address of the master. It is at this master where routers will run to allow for external clients to request application resources running within OpenShift.
- Read the following page carefully to make sure your VMs fit the needs of OpenShift: Installation Pre-requisites. Pay special attention to the Host Preparation section.
- Ensure you have pyOpenSSL installed on the master node as it was a missing dependency during the time of writing this article. You can install it via
yum -y install pyOpenSSL. - Run all the following steps as your login user as opposed to root on the master node.
Setup OpenShift using Ansible
Put the following lines into /etc/ansible/hosts. Update the values to fit your environment (hostnames):
[OSEv3:children]
masters
nodes
[OSEv3:vars]
ansible_ssh_user=myuser
ansible_sudo=true
deployment_type=origin
osm_default_subdomain=apps.example.com
osm_default_node_selector='region=primary'
openshift_master_identity_providers=[{'name': 'htpasswd_auth', 'login': 'true', 'challenge': 'true', 'kind': 'HTPasswdPasswordIdentityProvider', 'filename': '/etc/origin/htpasswd'}]
[masters]
originmaster.example.com
[nodes]
originmaster.example.com openshift_node_labels="{'region': 'infra', 'zone': 'dc1'}" openshift_schedulable=true
originnode1.example.com openshift_node_labels="{'region': 'primary', 'zone': 'dc1'}" openshift_schedulable=true
originnode2.example.com openshift_node_labels="{'region': 'primary', 'zone': 'dc1'}" openshift_schedulable=true
- Run Ansible:
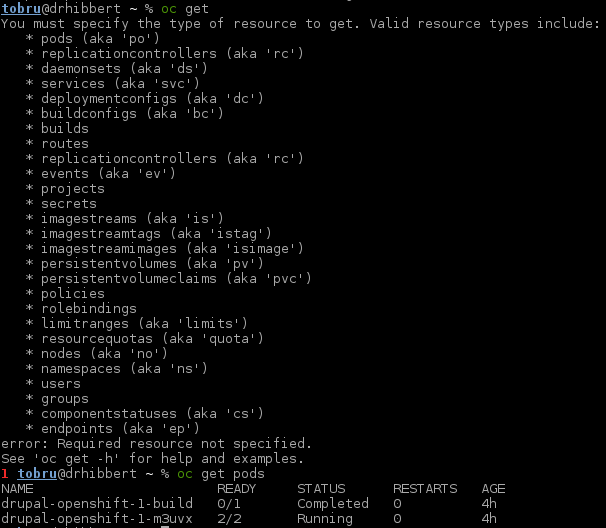
ansible-playbook playbooks/byo/config.yml - Check that everything went well via the OpenShift client. Your output should show 3 nodes with STATUS ready:
oc get nodes - Add a user to OpenShift:
sudo htpasswd /etc/origin/htpasswd myuser - Deploy the registry (additional details at Deploy Registry):
sudo htpasswd /etc/origin/htpasswd reguseroadm policy add-role-to-user system:registry regusersudo oadm registry --mount-host=/srv/data/registry --credentials=/etc/origin/master/openshift-registry.kubeconfig --service-account=registry
- Deploy the router (additional details at Deploy Router):
sudo oadm router --credentials=/etc/origin/master/openshift-router.kubeconfig --service-account=router
Add persistent storage
After these steps, one important piece is missing: Persistent storage. Running any application which stores application data will lose its data after migration to another OpenShift node after restarting, redeployment, and so on. Therefore we should add shared NFS storage. In our example, we will make this available by the master:
- Add the following line to /etc/exports:
/srv/data/pv001 *(rw,sync,root_squash) - Export the directory:
sudo exportfs -a - On all cluster nodes including the master, alter the SELinux policy in order to enable the usage of NFS:
sudo setsebool -P virt_use_nfs 1 - Create a file called
pv001.yamlwith the following content and create the obejct withoc create -f pv001.yaml:
apiVersion: "v1"
kind: "PersistentVolume"
metadata:
name: "pv001"
spec:
capacity:
storage: "30Gi"
accessModes:
- "ReadWriteOnce"
nfs:
path: "/srv/data/pv001"
server: "originmaster.example.com"
persistentVolumeReclaimPolicy: "Recycle"
You now have a 3-node OpenShift Origin cluster including persistent storage, ready for your applications! You can check the definition with: oc get pv.
Please note: This is a very minimal setup. There are several things to do before running in production. F.e. you could add some constraints to make sure that the router and registry only run on the master and all applications on the nodes. Other things to include into production deployment considerations: storage capacity, network segmentation, security, accounts. Many of these topics are discussed in the official OpenShift documentation.
Deploy applications
Now that the 3-node cluster is up and running, we want to deploy apps! Of course, that's the reason we created it in the first place, right? OpenShift comes with a bunch of application templates which can be used right away. Let's start with a very simple Django with PostgreSQL example.
Before you begin, fork the original GitHub project of the Django example application to your personal GitHub account so that you're able to make changes and trigger a rebuild. The intent here allows you to control webhook configurations for your fork to trigger code updates within OpenShift. Once done, then you can proceed to create the project within OpenShift.
- Login to https://originmaster.example.com:8443/ with the user created in step 4 above.
- Click on "New Project" and fill in all the fields. Name it myproject. After clicking on “Create” you're directed to the overview of available templates.
- Create a new app by choosing the django-psql-example template
- Insert the repository URL of your forked Django example application into the field
SOURCE_REPOSITORY_URL. All other fields can use their default value. By clicking on "Create" all required processes are started in the background automatically. - The next page gives you some important hints. To have the complete magic: To automate the delivery of new code via a deployment without human intervention, configure the displayed webhook URL in your Github project. Now every time you push code to your git remote on GitHub, OpenShift gets notified and will rebuild and redeploy your app without effort spent by a human. Please note that you probably need to disable SSL verification as by default a self-signed certificate is used which would fail verification
- Watch your new app being built and deployed on the overview page. As soon as this is finished, the app is reachable at http://django-psql-example-myproject.apps.example.com/
- To get the feeling of the full automation: Change some code in the forked project and push it to GitHub. After a few seconds, reload the page and you should see your changes active.
Scaling
One of the most exciting features in OpenShift is scaling. Let's say the above Django application is an online shop and you create some advertisement which will lead into more page views. Now you want to make sure that your online shop is available and responsive during this time. Simple as that:
oc get rc
oc scale rc django-psql-example-2 --replicas=4
oc get rc
The replication controller (rc) takes care of creating more Django backends on your behalf. Other components will make sure that these new backends are added to the router as load balancing backends. The replication controller also makes sure that there are always 4 replicas running, even if a host fails and there are enough hosts available on the cluster to run the workload on.
Scaling down is just as easy as scaling up, just adjust the --replicas= parameter accordingly.
Another application
Now that we've deployed and scaled a default app, we want to deploy a more customized app. Let's use Drupal 8 as an example. Drupal is a PHP application which uses MySQL by default, so we need to use the matching environment for this. Set it up via the following command:
oc new-project drupal8
oc new-app php~https://github.com/tobru/drupal-openshift.git#openshift \
mysql --group=php+mysql -e MYSQL_USER=drupal -e \
MYSQL_PASSWORD=drupalPW -e MYSQL_DATABASE=drupal
This long command needs a bit of explanation:
- oc: Name of the command line OpenShift client
- new-app: Subcommand to create a new application in OpenShift
- php~: Specifies the build container to use (if not provided the S2I process tries to find out the correct one to use)
- https://github.com/tobru/drupal-openshift.git: Path to the git repository with the app source to clone and use
- #openshift: Git reference to use. In this case the openshift branch
- mysql: Another application to use, in this case a MySQL container
- –group=php+mysql: Group the two applications together in a Pod
- -e: Environment variables to use during container runtime
The new-app command uses some special sauce to determine what build strategy it should use. If there is a Dockerfile present in the root of the cloned repository, it will build a Docker image accordingly. If there is no Dockerfile available, it tries to find out the project's language and uses the Source-to-Image (S2I) process to build a matching Docker image containing both the application runtime and the application code.
In the example above we specify to use a PHP application container and a MySQL container to group them together in a pod. To successfully execute the MySQL container a few environment variables are needed.
After the application has been built, the service can be exposed to the world:
oc expose service drupal-openshift --hostname='drupal8.apps.example.com'
As the application repository is not perfect and the PHP image not configured correctly for Drupal (perhaps we hit the issue #73!), we need to run a small command inside the pod to complete the Drupal installation. Substitute ID with the ID of your running pod which is visible via oc get pods):
oc exec drupal-openshift-1-ID php composer.phar install
Now navigate to the URL drupal8.apps.example.com and run the installation wizard. You'll want to set the DB host to "127.0.0.1" as “localhost” doesn't work as you might expect.
At the end there is still a lot to do to get a "perfect" production-grade Drupal instance up and running. For example it is probably not a good idea to run the application and database in the same pod because it makes scaling difficult. Scaling a pod up scales all Docker images contained within the pod. This means that the database image also needs to know how to scale, which is not the default case. In it's heart, scaling means just spinning up another instance of a Docker image, but that does not mean that the user generated data is automatically available to the additional running Docker images. This needs some more effort put in.
The best thing here would be to have different pods for the different software types: One pod for the Drupal instance and one pod for the database so that they can be scaled independently and the task of replicating user generated data can be done tailored to the softwares need (which is of course differently between a web server and a database server).
Also there is persistent storage missing in this example. Every uploaded file or other working files will be lost when the pod is restarted. If you want more information on how to most effectively add persistent storage, here is a very good blog post describing it in detail: OpenShift v3: Unlocking the Power of Persistent Storage.
Helpful commands
When working with OpenShift, it's useful to have some commands ready that help getting information or show what is going on.
OpenShift CLI: oc
The OpenShift CLI "oc" can be installed on your computer, see Get Started with the CLI. Before issuing an oc command, you must login to the OpenShift master with oc login. It will ask for an URL to the master (if started for the first time) and for a username and password.
oc whoami
If you can't remember who you are, this tells it to you.oc project $NAME
Shows the currently active project to which all commands are run against. If a project ame is added to the command then the currently active project changes.oc get projects
Displays a list of projects to which the current user has access tooc status
Status overview of the current projectoc describe $TYPE $NAME
Detailed information about an object.oc describe pod drupal-openshift-1-m3uvxoc get event
Shows all events in the current project. Very useful for finding out what happened.oc logs [-f] $PODNAME
Show the logs of a running pod. With -f it tails the log much like tail -f.oc get pod [-w]
List of pods in the current project.
With -w it shows changes in pods. Note: watch oc get pod is a helpful way to watch for pod changesoc rsh $PODNAME
Start a remote shell in the running pod to execute commandsoc exec $PODNAME $COMMAND
Execute a command in the running pod. The command's output is sent to your shell.oc delete events --all
Cleanup all events. Useful if there are a lot of old events. Events are information about what is going on on the API objects and what problems exist (if there are any).oc get builds
List of builds. A build is a process of creating runnable images to be used on OpenShift.oc logs build/$BUILDID
Build log of the build with the id "buildid". This corresponds to the list of builds which are displayed with the command above.
Commands to run on the OpenShift server
The OpenShift processes are managed by systemd. All logs are written to the systemd journal. So the easiest way to get information about what is going on it to query the system journal:
sudo journalctl -f -l -u docker
System logs of Dockersudo journalctl -f -l -u origin-master
System logs of Origin Mastersudo journalctl -f -l -u origin-node
System logs of Origin Node
Some more interesting details
Router
The default router runs HAproxy which is dynamically reconfigured should new services be requested to be routed by the OpenShift client. It also exposes its statistics on the router's IP address over TCP port 1936. The password to retrieve this is shown during the application's deployment or it can be retrieved by running oc exec router-1-<ID> cat /var/lib/haproxy/conf/haproxy.config | less. Look for a line beginning with "stats auth".
Note: for some reasons an iptables rule was missing on my master node preventing my getting at the router statistics. I added one manually to overcome via sudo iptables -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 1936 -j ACCEPT.
Logging
OpenShift brings a modified ELK (Elasticsearch-Logstash-Kibana) stack called EFK: Elasticsearch-FluentD-Kibana. Deployment is done using some templates and the OpenShift workflows. Detailed instructions can be found at Aggregating Container Logs in the OpenShift documentation. When correctly installed and configured as described under the above link, it integrates nicely with the web interface. These steps are not part of the Ansible playbooks and need to be carried out manually.
Metrics
Kubernetes Kubelets gather metrics from running pods. To collect all these metrics, the metric component needs to be deployed similar to the logging component via OpenShift workflows. This is also very well documented at Enabling Cluster Metrics in the OpenShift documentation. It integrates into the web interface fairly seamlessly..
Failover IPs
Creating a highly available service most of the time involves having IP addresses be made highly available. If you want to have a HA router, there is the concept of IP failover available within OpenShift. This means you configure an IP address as a failover address and attach it to a service. Under the hood, keepalived now keeps track of this IP and makes it highly available using the VRRP protocol.
IPv6
I couldn't find much information about the state of IPv6 in OpenShift. But it seems problematic right now, as far is I can see. Docker is supporting IPv6 but Kubernetes seems to lack functionality: Kubernetes issue #1443
Lessons learned so far
During the last few months while making myself familiar with OpenShift I've learned that the following points are very important in understanding OpenShift:
- Learn Kubernetes
This is the main building block in OpenShift, so a good knowledge is necessary to get around the concepts of OpenShift. - Learn Docker
As this is the second main building block of OpenShift, it's also important to know how it works and what concepts it follows. - Learn Twelve-Factor
To get the most out of a PaaS, deployed applications should closely follow the Twelve-Factor document.
Some other points I learned during experimenting with OpenShift:
- The Ansible playbook is a fast moving target. Most of the time the paths written in the documentation don't match the Ansible code sadly. Also some things didn't work well, for example upgrading from Origin 1.0.8 to Origin 1.1.0.
- OpenShift heavily depends on some features, such as SELinux, which are by default only present on Red Hat-based Linux distributions. This makes it hard to go about getting OpenShift working on Ubuntu-based Linux distributions without things quickly becoming a yak shaving exercise. In theory it should be possible to run OpenShift on all distributions supporting Docker and Kubernetes, but as always the devil lies in the details.
- Proper preparation is the key to success. As OpenShift is a complex system, preparation helps to get a working system. This is not only preparing VMs and IP addresses, but also preparing knowledge, like learning how everything works and try it out in a test system.
Some more technical learnings:
- When redeploying the registry the master needs to be restarted, as the master caches the registry service IP. This is possible via:
sudo systemctl restart origin-master - Before running applications on OpenShift it makes sense to run the diagnostics tool using: sudo openshift ex diagnostics
Automate all the things!
The friendly people at Puzzle are working on a Puppet module to make the OpenShift installation and configuration as automated as possible. Internally it calls Ansible to do all the lifting. While it doesn't make sense to re-implement everything in Puppet, the module helps with manual tasks that have to be carried out after having OpenShift installed by Ansible. For an already existing Puppet environment, this is great to get OpenShift integrated.
You can find the source on GitHub and help to make it even better: puzzle/puppet-openshift3.
Conclusion and Thanks
This blog post only touches the tip of the iceberg regarding OpenShift and its capabilities as an on-premise PaaS. It would need many books to cover all of this very exciting technology. For me it's one of the most thrilling piece of technology since many years and I'm sure it will have a bright future!
If you are interested in running OpenShift in production, I suggest doing a proof-of-concept fairly early. Be prepared to read and plan a lot. Many important topics such as monitoring, security, backup were not covered here and are important topics for a production-ready PaaS
For those wanting additional reading materials on OpenShift, here are some additional links with lots of information:
- https://docs.openshift.org/
- http://www.openshift.org/
- http://lists.openshift.redhat.com/openshiftmm/listinfo
- https://blog.openshift.com/
- https://www.openshift.tv/
- https://github.com/openshift/training
- https://github.com/openshift/origin/tree/master/examples
I want to thank everyone who helped me with this blog, especially my workmates at VSHN (pronounced like vision / vĭzh'ən) and our friends at Puzzle ITC. And another special thank goes to Nick Silkey (@filler) for being the editor of this article.
If you have any comments, suggestions or if you want to discuss more about OpenShift and the PaaS topic, you can find me on Twitter @tobruzh or on my personal techblog called tobrunet.ch.

{kind=link}